Neural Network Notation - From Arrows to Weight Matrices
Decode neural network notation through a rocket launch story. Learn layers, weight subscripts, Wᵀ, hidden-layer scores, and how vectorization scores a whole dataset at once.
The Launch Log Comes First
A rocket team keeps a small launch log.
Before every launch attempt, Mission Control records a few clues and makes one call:
GO or HOLD?
Deep learning notation starts here.
Not with symbols.
What the Launch Log Has
Mission Control keeps a small launch log.
Each row is one launch attempt.
Each column records one thing about that attempt.
The table has only four columns:
- Launch ID is just the row name. It identifies the attempt, but it is not a launch clue.
- Wind records the wind speed before launch.
- Fuel records how much fuel is ready.
- Launch records the final call: GO or HOLD.
The model will look at Wind and Fuel.
The model learns the final call: GO or HOLD.
From Brain Cells to Rocket Brains
A biological neuron receives many signals.
If the combined signal is strong enough, it activates and sends a new signal forward.
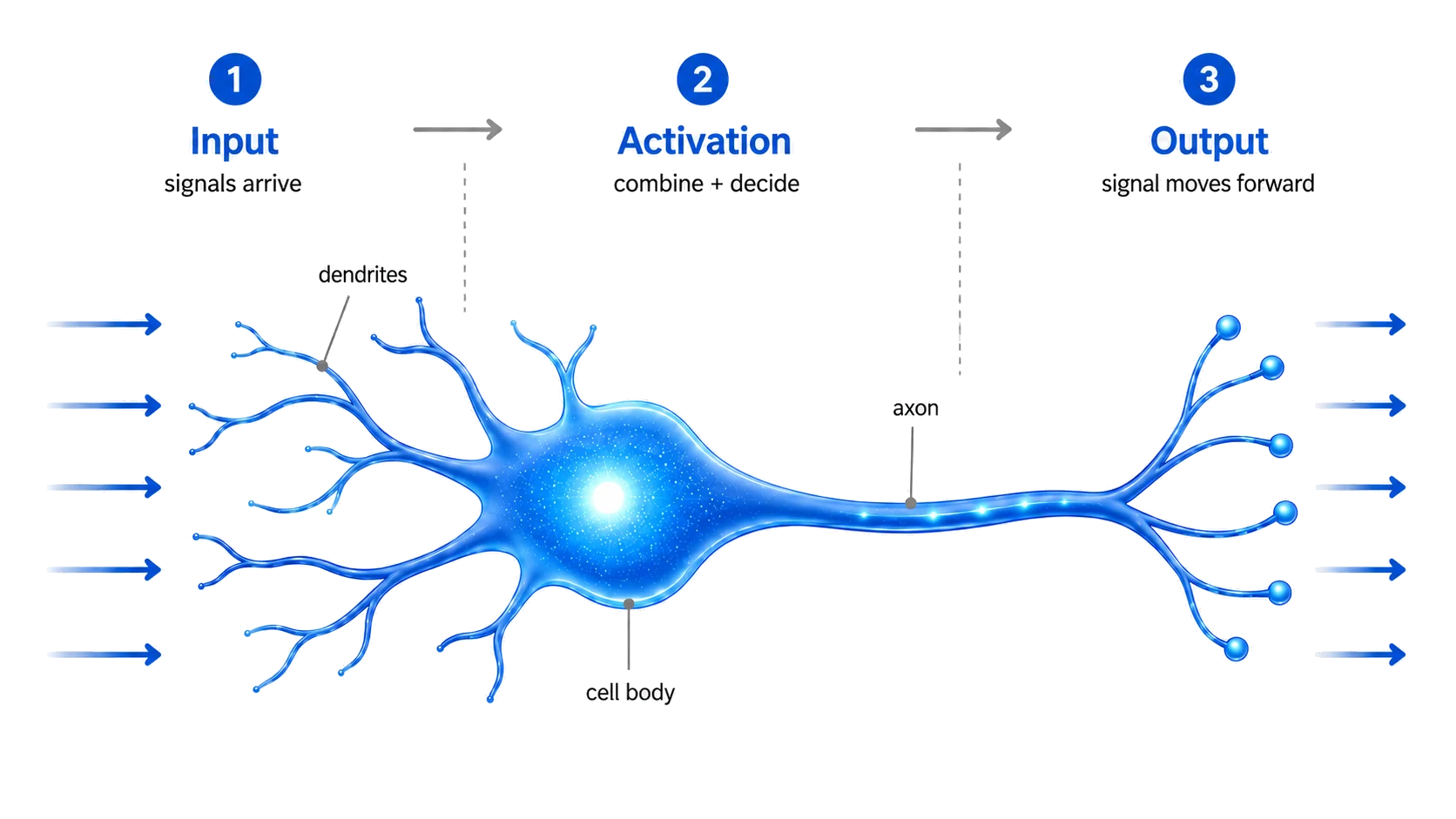
Artificial neurons borrow that flow:
inputs come in → activation happens → output goes out
In our rocket story, the inputs are simple: Wind and fuel.
The clues move through the network until it makes the final call: GO or HOLD.
Control Wind and Fuel to help the rocket launch.
If the final Launch value reaches 60% or higher, Mission Control says GO.
If it stays below 60%, the rocket stays on the pad.
Reading the Network Picture
In the network picture, Wind and Fuel are input values.
They are the clues entering the network.
They are not neurons.
The two middle circles are neurons.
Both neurons receive the same input values:
Wind.
Fuel.
But they do not have to listen to them the same way.
Each neuron gives Wind and Fuel its own level of trust.
Then each one sends a signal forward.
Those two signals become the inputs for the final neuron.
The final neuron combines them one more time.
That final result becomes the network’s call:
GO or HOLD.
So this tiny network has three artificial neurons:
Two hidden neurons + one output neuron
Zooming Into One Neuron
The network picture shows several circles.
Let’s zoom into Activation 1, one neuron in the middle of the network.
Input:
It receives two inputs:
Here, x simply means input.
So is the first input, and is the second input.
Weights:
But Activation 1 does not trust both inputs equally. It asks:
- How much should I listen to Wind?
- How much should I listen to Fuel?
Those “how much should I listen?” numbers are called weights.
For Activation 1, the neuron gives more influence to Fuel and less influence to Wind:
In plain English:
Fuel carries more influence here, but Wind still matters.
Net Input:
Now the neuron combines the inputs and weights into one score.
That score is called the net input.
We denote it by :
For Activation 1, that becomes:
It is the neuron’s total faith after weighing both clues: Wind and Fuel.
Threshold:
But is just a number, not GO or HOLD yet.
To turn that number into a decision, the neuron compares it to a threshold.
We denote that threshold by .
If reaches or crosses , the neuron says GO.
If stays below , the neuron says HOLD.
Earlier, the simulation used 60% as the threshold for launch.
So the rule becomes:
That symbol is the activation function.
Activation Function:
Activation function converts the score into a clean output:
This is called a step function because it starts at 0 and, once the score crosses the threshold, jumps to 1.
Because the jump has a size of 1, this version is also called a unit step function.
Drag z across the graph and watch what happens when z reaches θ = 60.
Bias:
There is one more small trick.
So far, the neuron compares the score to a threshold:
In our rocket example:
That means:
But real neural networks usually do not carry the threshold around separately.
They shift the threshold to zero using a mathematical trick:
Now the new decision rule is simpler:
The threshold line is now zero.
That hidden shift behaves like a bias term.
So the threshold is folded into the net input as :
Think of bias as the launch system’s starting adjustment before it judges Wind and Fuel.
The question is no longer:
Is the bias positive or negative?
The better question is:
Did bias move the score closer to the launch line or farther away?
Notice in the example above, the dotted bias line sits at:
The dotted line shows the bias push, not the final score.
The final score is still the green dot.
That places bias on the launch side of the zero line.
So this bias makes the network more lenient toward launch.
For example, suppose the weighted clues produce:
By itself, the neuron says HOLD.
With bias 12:
Closer, but still below zero.
Still HOLD.
With bias 20:
Now the score crosses zero.
The neuron says GO.
Bias does not change Wind or Fuel.
Bias changes how much help the score gets before the final check:
The neuron still asks:
Did the score cross the line?
Bias just changes how close the score starts to that line.
🧭 Notation Checkpoint
Before we zoom out to matrix notation, here is the notation we just met:
| Symbol | Reads as | Meaning in our rocket story |
|---|---|---|
| input | One clue entering the neuron | |
| first input | Wind | |
| second input | Fuel | |
| weight | How much the neuron listens to an input | |
| first weight | Influence of Wind | |
| second weight | Influence of Fuel | |
| net input | The weighted score before the final decision | |
| threshold | The launch line the score must cross | |
| activation function | The rule that turns the score into output | |
| bias | The starting adjustment that moves the score closer to or farther from the launch line |
The whole neuron can now be read as:
Then the activation function asks:
Writing the Same Neuron in Matrix Notation
So far, we wrote the neuron one piece at a time:
That is clear, but it gets tiring fast.
If a rocket launch has two clues, this is fine.
If it has twenty clues, the formula becomes a long grocery receipt.
Matrix notation is the shortcut.
It lets us pack the inputs and weights into neat columns.
One Launch Attempt as a Vector
For one launch attempt, the neuron watches two clues:
Matrix notation stacks them into one input vector:
The weights can be stacked the same way:
So one launch attempt gives the neuron two vectors:
The inputs say what the neuron sees.
The weights say how much the neuron listens to each input.
In books, you may see the same column vector written sideways like this:
That compact notation means the same thing as:
Books write it sideways to save vertical space, but the semicolon tells you it is still a column vector.
Dot Product: The Short Version of the Score
The neuron still needs the score:
The weighted part is:
We already stacked the inputs and weights as vectors:
To multiply them, we transpose the weight vector:
Now the weighted part can be written as:
This row-times-column operation is called a dot product.
Now we add bias to the score:
In this one-neuron version:
- gives one weighted score
- gives one bias adjustment
- becomes one final score
Same neuron.
Cleaner notation.
From One Launch Attempt to a Matrix
So far, the neuron scored one launch attempt:
That is useful, but real training data is not one row.
It is a table.
Single row input:
One launch attempt has two input features:
For one launch attempt, we can write those two values as one row:
Here is the small notation trick:
RC = Row, Column.
This is the same RC idea from the earlier Machine Learning Notation guide.
Machine Learning Notation Review the RC memory hook.Now read the two symbols in that row:
Both values come from launch attempt 1.
But they sit in different feature columns.
That is one launch attempt.
Matrix input:
Now add a second launch attempt.
The table grows downward:
This is the first big jump.
Lowercase was one launch attempt.
Capital is a collection of launch attempts.
So with two launch attempts and two features, has shape:
Scoring the matrix with
The number of weights is tied to the number of features, not the number of launch attempts.
We could have one launch attempt, ten launch attempts, or a full logbook.
But if each launch attempt has two features, the neuron needs two weights:
For one launch attempt, we used:
That gave one weighted score.
But now we are no longer scoring one launch attempt.
We are scoring the whole launch logbook.
So the notation changes:
scores one launch attempt.
scores every launch attempt in .
The dimensions explain why:
That gives one weighted score for one launch attempt.
But the launch logbook has many rows:
That gives one weighted score for each launch attempt.
Same idea.
Different organization.
For the two-row launch logbook:
Same weights.
Two launch attempts. Two weighted scores.
Adding bias
Now add bias.
The bias is one adjustment value:
But returns a column of weighted scores:
So when we write:
we mean:
The same bias is applied to each launch attempt’s weighted score.
So becomes a column of final scores:
One final score per launch attempt.
General shape
If the launch logbook has launch attempts and input features, then has shape:
The weight vector needs one weight per feature, so has shape:
Now the shape of is:
So gives scores — one per launch attempt.
Then bias shifts the score column:
The bias is added to each score:
So becomes the final score column.
In code, you usually do not manually build that repeated bias column.
You pass once, and the library applies it across the score column.
lowercase is one launch attempt.
capital is the launch logbook.
scores the whole logbook.
From scores to decisions
Now is a column of scores.
But raw scores are not the goal — HOLD or GO is.
The activation function converts scores into decisions:
The hat matters.
means the model’s prediction.
It is not the actual ground-truth label .
So in our rocket story:
- is what really happened: GO or HOLD
- is what the neuron predicted: GO or HOLD
A step function is one kind of activation function:
So each score becomes a decision:
One decision per launch attempt.
Insight: is the score.
is the decision.
🧭 Matrix Notation Checkpoint
Here is the capital notation we just met:
| Symbol | Shape | Meaning |
|---|---|---|
| Full launch logbook | ||
| One weight per feature | ||
| One weighted score per launch attempt | ||
| repeated across scores | Bias adjustment | |
| Final score column | ||
| Activation applied to each score | ||
| Prediction column |
Memory hook:
is the launch logbook. scores it. turns scores into predictions.
Mission Control Briefing
Capital X: The Full Logbook
Mission Control opens the binder of launch attempts. That full table is X.
Capital X: The Full Logbook. Mission Control opens the binder of launch attempts. That full table is X.
Quiz
86% of people love quizzes after learning. Are you one of them?
Question text
Quiz complete