Articles
 From Probability Distributions to Loss Functions Learn how maximum likelihood connects distributions to loss functions, why raw likelihood underflows, and how negative log-likelihood makes training possible. June 5, 2026
From Probability Distributions to Loss Functions Learn how maximum likelihood connects distributions to loss functions, why raw likelihood underflows, and how negative log-likelihood makes training possible. June 5, 2026 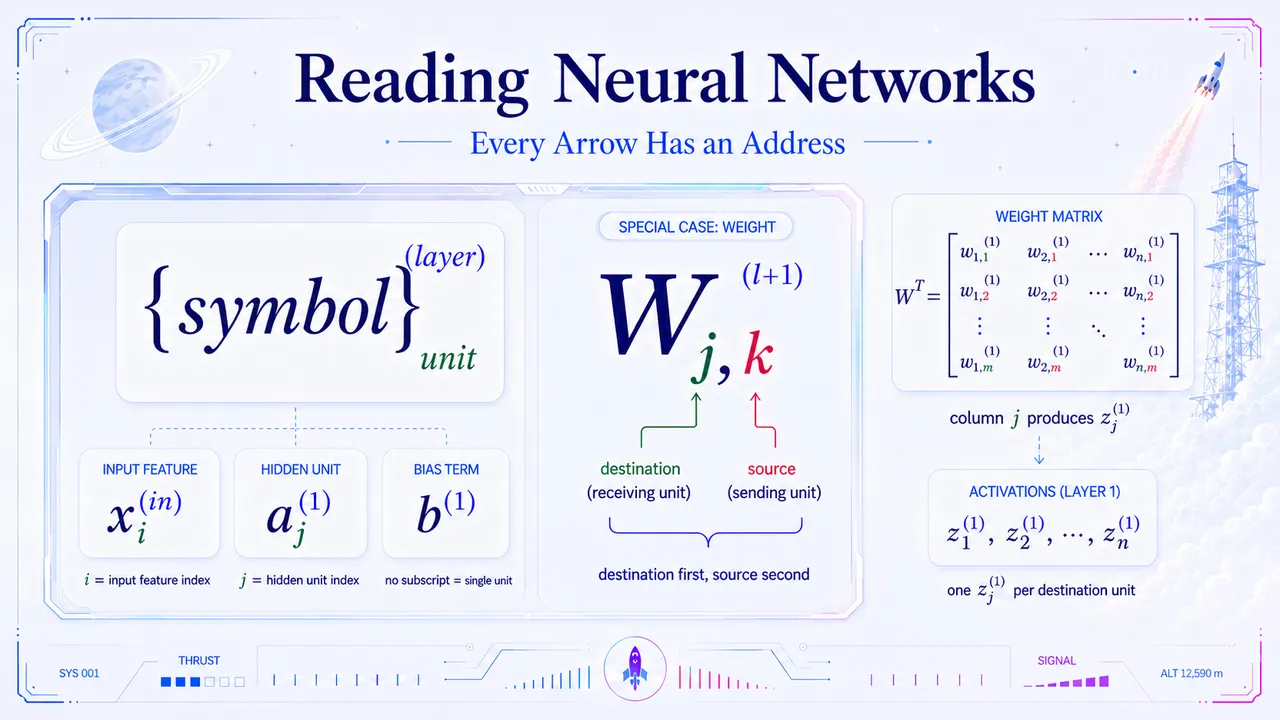 Reading Neural Networks - Every Arrow Has an Address Learn how to read a fully connected neural network diagram — from layers and activations to weight matrices, subscripts, and arrow labels. June 4, 2026
Reading Neural Networks - Every Arrow Has an Address Learn how to read a fully connected neural network diagram — from layers and activations to weight matrices, subscripts, and arrow labels. June 4, 2026 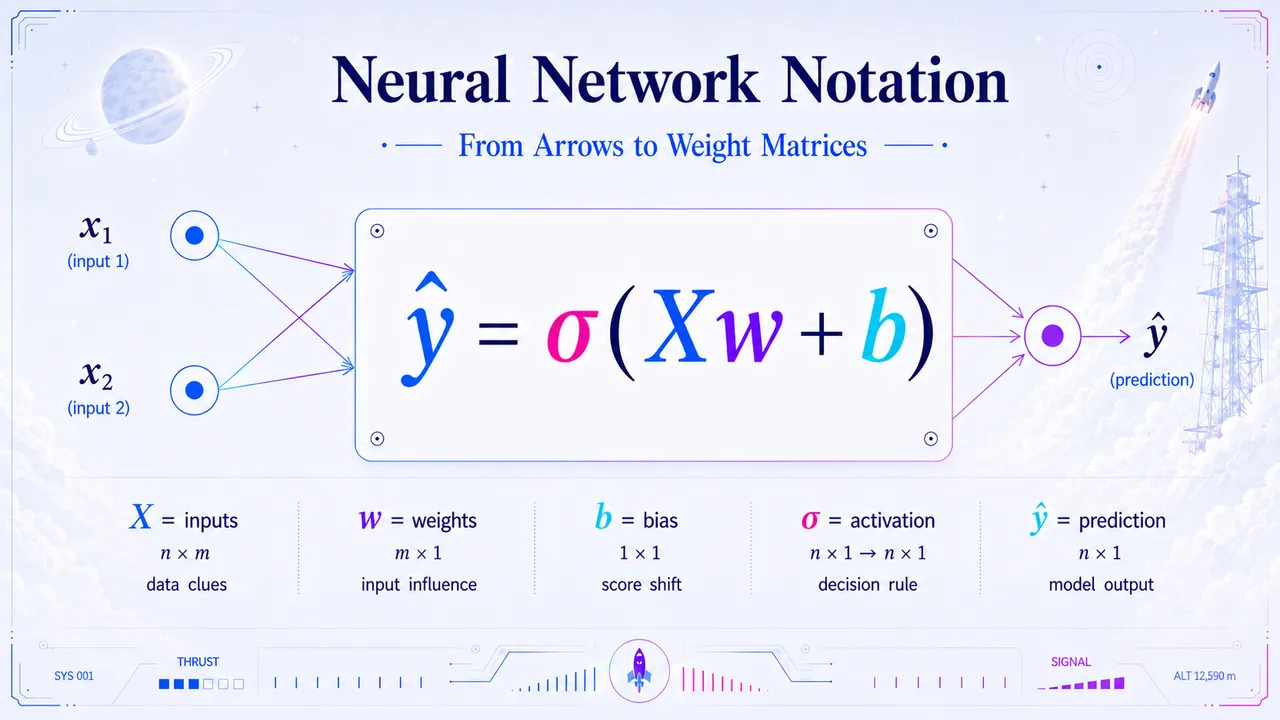 Neural Network Notation - From Arrows to Weight Matrices Decode neural network notation through a rocket launch story. Learn layers, weight subscripts, Wᵀ, hidden-layer scores, and how vectorization scores a whole dataset at once. June 1, 2026
Neural Network Notation - From Arrows to Weight Matrices Decode neural network notation through a rocket launch story. Learn layers, weight subscripts, Wᵀ, hidden-layer scores, and how vectorization scores a whole dataset at once. June 1, 2026 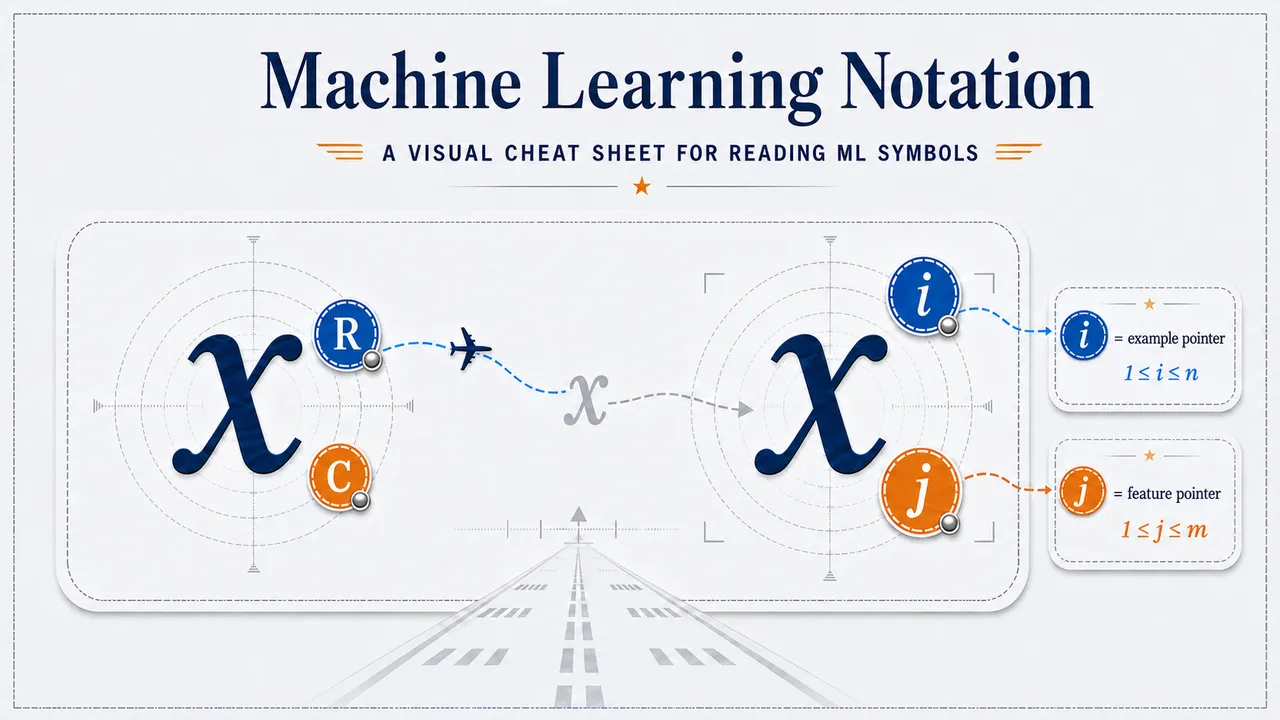 Machine Learning Notation - From Flight Logs to Symbols Decode the secret language of machine learning notation through an RC flight log story — from rows and features to inputs, labels, indexed values, and predictions. June 1, 2026
Machine Learning Notation - From Flight Logs to Symbols Decode the secret language of machine learning notation through an RC flight log story — from rows and features to inputs, labels, indexed values, and predictions. June 1, 2026 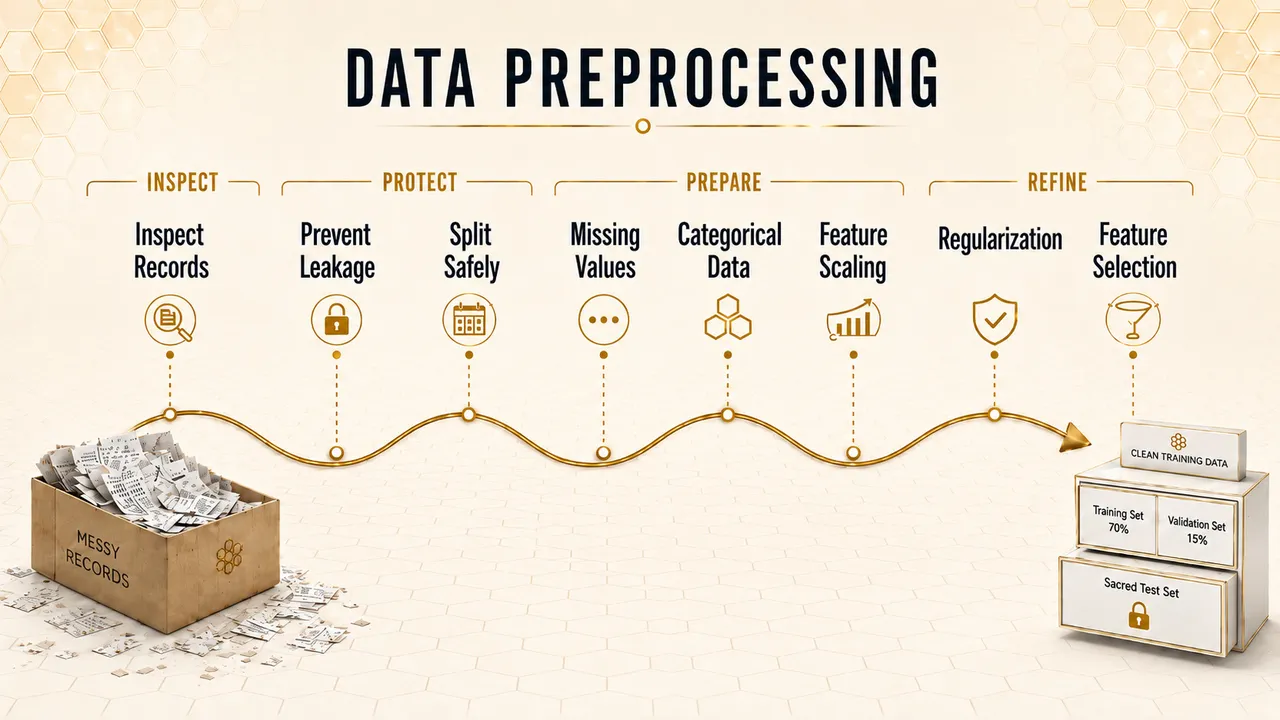 Data Preprocessing for Machine Learning: Transforming Messy Logs into Clean Training Data The quest to predict hive health begins with a messy shoebox of hive logs. Follow HiveDoctor as raw records become clean training data for spotting hives in trouble. May 28, 2026
Data Preprocessing for Machine Learning: Transforming Messy Logs into Clean Training Data The quest to predict hive health begins with a messy shoebox of hive logs. Follow HiveDoctor as raw records become clean training data for spotting hives in trouble. May 28, 2026  Regularization: Stop Your Model From Chasing Every Buzz YieldMaster looks perfect on spring records, but perfect training charts can hide overfitting. Learn how regularization adds restraint: L1 cuts, L2 calms. May 23, 2026
Regularization: Stop Your Model From Chasing Every Buzz YieldMaster looks perfect on spring records, but perfect training charts can hide overfitting. Learn how regularization adds restraint: L1 cuts, L2 calms. May 23, 2026  Agentic Architecture: A Goal-Driven System Understand AI agent architecture with a robot beekeeper story covering agentic loops, tool calls, memory, guardrails, multi-agent systems, and observability. May 17, 2026
Agentic Architecture: A Goal-Driven System Understand AI agent architecture with a robot beekeeper story covering agentic loops, tool calls, memory, guardrails, multi-agent systems, and observability. May 17, 2026  Confusion Matrix, Precision, Recall and F1 - Sherlock’s Fraud Case Sherlock Holmes investigates fraud while uncovering accuracy, precision, recall, and F1 score through the confusion matrix. May 7, 2026
Confusion Matrix, Precision, Recall and F1 - Sherlock’s Fraud Case Sherlock Holmes investigates fraud while uncovering accuracy, precision, recall, and F1 score through the confusion matrix. May 7, 2026  LLM City and Tokens Explore LLM City, where words become currency — a fable that makes tokens click. May 9, 2026
LLM City and Tokens Explore LLM City, where words become currency — a fable that makes tokens click. May 9, 2026